Build QA Bot from Dumped Dialog
author: Xuan Wang
1. Intro
This is a summary from my work in Laiye, Inc. I will be mainly looking at the processes not specific algorithems or models.
1.1 Our Context
Customer service covers from presale to postsale, traditionally this work relies heavily on humans. But with a QA bot, we can:
- alleviate CSR’s(Customer Service Representitive) workload, and raise the efficiency, (statistics from Laiye, Inc has shown a leap from 1:100 CSR-User rate to 1:400!)
- standardize the service and its quality, enable the company to accumulate and develop its knowledge base
- build a positive loop of “knowledge base - QA bot - human labeling”, also note that we include human in the loop, which not only put a little cusion between QA bot and users but as well provide labeling to the dialog data
1.2 System Overview
The leading QA bots nowadays follow a cascade pattern of “Search” and “Rerank”:
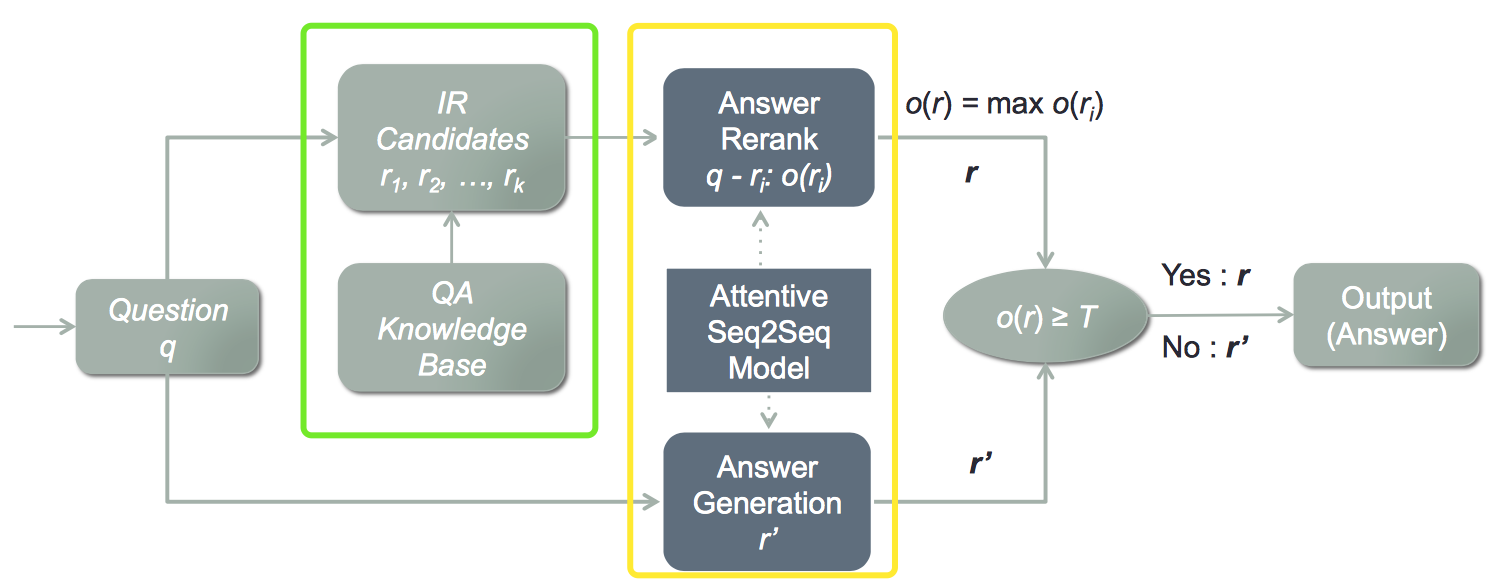 courtesy: AliMe Chat
courtesy: AliMe Chat
First, the search engine(the green part) retrieves some number of response candidates; then hand those to reranking system(the yellow part) to do a finer-grained ranking to output.
The reason to this design is to reduce the response time while maintain the most recall. Search engine is flashing fast but lacks of the ability to capture semantics. So reranking system is thus designed to make up. Reranking system is modeled more complicatedly, e.g. using deep networks, and usually it is intolerable to feed all candidates from knowledge base to it. So, we stack them.
Here we talk about the reranking system.
1.3 Multi-turn Reranking System
In production cases, a dialog about a topic may includes multiple turns of utterances. One can use slot fitting to collect all the arguments if it is in a taskbot setting when an API is meant to be called. But in our case, we only have the knowledge base at hand(i.e. logs of questions and answers), so we do not have predefined slots to fit. Thus if we want to capture more contextual information, we need to look further back to take more utterances into account, which means a “multi-turn” model.
My model is a reimplementation of Sequential Matching Networks.
1.4 Terminology

2. Corpus Preparation
2.1 Wrangling
What we have is historical dumped dialog data, cleansing works include(non-exhaustively):
- remove {illegal chars, timestamps/sys log/ID info or other tags, …}
- combine consecutive utterances from the same ID into the one
- split out sessions(e.g. by ‘\n’)
If you don’t have a satisfying amount of data, you may want to try some data augmentation, e.g. shuffling in small granularities.
2.2 Make Train/Valid/Test Sets
2.2.1. Pick a window size, slide through
Say if we consider three turns, then it will be a total of 3 * 2 = 6 utterances, so the window size will be 6.
2.2.2. Mix in negative samples
We assume all the responses from CSRs are gold answers, but since our system is a scoring system, we need to train with negative samples otherwise the system will just learn to always give a high score.
For every context, random draw a response from corpus to it to make a negative sample. Train set mix at 1:1, valid and test 1:9. Train set best to keep a balance between positive and negative samples, but valid and test are best to be decided according to the actual business. For example if the production system returns 10 candidates, then we should recall from the 10, so we mix valid and test at a rate of 1:9. But the final system may have several good candidates, which is when we need human to evaluate subjectively.
3. Vocabulary and Embedding Preparation
3.1 User-defined words
A major difference of Chinese NLP from English is we need to do word segmentation first. Typically a tokenizer is used, such as “jieba”. But for domain specific task we need to expand the built-in vocabulary of the tokenizer so that those domain specific words can be captured.
Note, we must make sure:
Always make the vocabulary consistent when 1)train embeddings, 2)train model and 3)online serving.
Concretely, add user-defined words after import jieba immediately. This bunch words should also keep the same version with upstream searching teammates.
3.2 Embeddings Preparation
3.2.1. Collect corpus
Collect in-domain articles, together with our dumped dialog data.
3.2.2 Export two files after done training embeddings:
 In fact
In fact w2i and w2v have two more vectors than embeddings, namely <PAD> and <UNK>.
4. Offline Stage
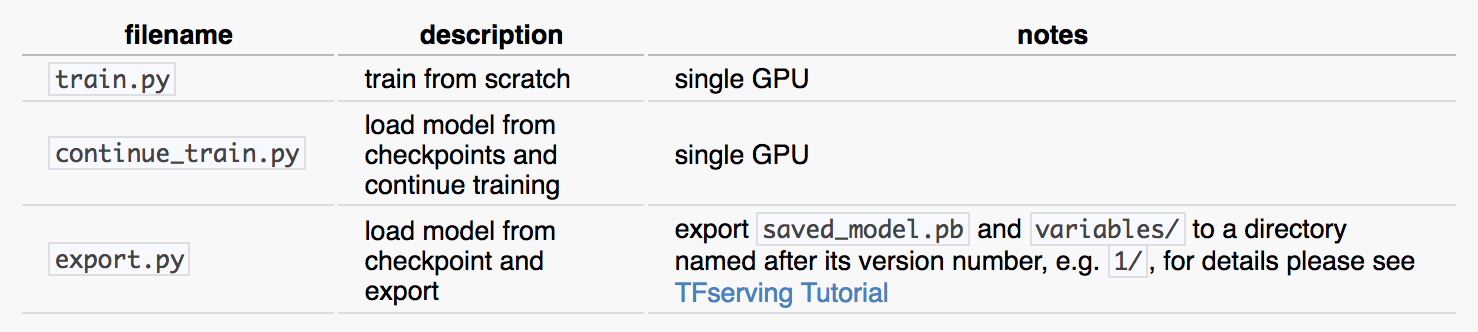
Codes Needed
5. Online Stage
Just need to be familiar TFserving. Server side code can adopt from Tensorflow’s official ranking serving code, but pay a little more attention to client side.
Still one thing to reiterate:
Always make the vocabulary consistent when 1)train embeddings, 2)train model and 3)online serving.
客服场景下由历史语料构建自动回复系统
作者: 王玄
1. 引入
本文由作者在助理来也公司的工作总结而来. 着重讨论流程步骤, 不涉及具体代码和算法模型本身.
1.1 场景说明
客服-用户对话场景是一种很广泛常见的场景, 覆盖从售前到售后的全过程. 在传统上这一部分属于人力密集性, 需要投入对客服人员的前期培训以及运营精力. 自动回复系统的构建可以:
- 减少客服工作压力提高效率, (在助理来也的实践中从1:100的客服-用户比提升到了1:400);
- 标准化服务内容和质量. 企业可以积累以及构建知识库, 筛选出标准化的话术进行回复.
- 构建”知识库-自动回复系统-人工标注”的良性闭环. 注意到自动回复系统到用户之间可以经过客服的缓冲, 这部分online labeling既保证了回复的质量, 又拥有了对数据的标注.
1.2 自动回复系统总览
目前前沿的自动回复系统的实现是以”检索”与”重排”两个子系统级联的方式:
图片来源: AliMe Chat
由检索(绿色部分)从知识库中第一级粗粒度筛选出一定数目的候选回复, 再交给重排(黄色部分)进行细粒度排序, 最后输出. 这样做的目的是为了在损失很少召回的前提下极大地提高了响应速度. 因为检索的速度很快, 而重排系统往往设计复杂且采用深层神经网络模型, 所以如果知识库里的全部回复都交由重排系统来排序, 响应速度会很慢.
这里主要将重排系统.
1.3 多轮重排系统
在实际的场景中, 经常有可能出现的情况是同一个目的的信息会通过好几句话才补充全. 类似的情况在taskbot中调用API时候需要用slot fitting策略来分轮次将API中的各个参数填补. 然而此时我们的场景是只拥有知识库(即历史上的问题和回答的日志), 并不能用slot fitting的策略来定. 所以如果我们要尽可能多获得上文的信息, 就需要不仅考虑最近的一句用户的utterance, 需要look further back, 也就是”多轮”的意义.
我们的模型用tensorflow重写了Sequential Matching Networks.
1.4 名词/术语说明

2. 语料准备
2.1 清洗和整理
数据是historical dump data, 需要先进行清洗, 包括但不限于:
- 去除 {非法字符, 时间戳/系统log/用户客服id等附加信息, …}
- 合并同一id连续发出的语句成一句话
- 不同的session之间切分开(比如说用空行分割)
这里如果是数据量比较小的情况下, 在这一步可以做一些数据增强的工作, 比如粒度比较小(词/句)的一些shuffle.
2.2 构造train/valid/test三个集合
2.2.1. 根据模型考虑的上文utterance个数, 确定窗口大小, 滑动切分经过2.1步骤后的数据
比如: 如果是考虑3轮会话, 则总共是3 * 2 = 6句utterance, 则窗口大小为6.
2.2.2. 混入负样本
由于历史语料中我们假设所有的客服回复都是gold answer, 但是我们的系统是一个打分系统, 需要负样本才可以进行训练. 对于每一个context, 随机从语聊中选择response与其进行拼接, 即构造出一个负样本. train set按正负1:1混合, valid和test按照1:9混合. train set按照1:1混合的目的是为了训练集的正负样本平衡. valid和test的混合方式根据业务实际来定, 比如说实际的模型会返回10个候选答案, 那么我们的召回就在10个里面, 所以选择1:9来进行混合. 当然知识库里面可能会有多个候选答案都可以作为答案, 这时的最后模型评价就需要人工的介入.
3. 词表以及embeddings的准备
3.1 user-defined词表准备
分词工具选用jieba, 在其上进行扩展.
要务必注意注意:
1)生成embeddings, 2)训练模型 以及 3)serving上线 时`jieba`的vocabulary务必保持一致.
具体地, 即在import jieba之后立即扩展同一份user-defined词表. 同时这份词表也可能也需要和上游的检索沟通, 确保分词结果的相容.
user-defind词表里有领域词汇, 产品相关的词汇等.
3.2 embeddings的准备
3.2.1. 语料收集
收集领域相关文章, 并上我们的语料本身.
3.2.2. 在训练好embeddings之后, 需要依次导出模型需要用的两个pickle文件:
 实际的
实际的w2i以及w2v比embeddings多两个向量, 分别对应<PAD>和<UNK>.
4. 模型离线阶段
离线阶段需要的基本代码

上述的train.py和continue_train.py在考虑实际硬件资源是可以有多GPU的multi-towered版本, 加速训练.
5. 模型上线阶段
这部分只需要熟悉下TFserving本身即可, server部分的代码可以套用tensorflow官方提供的ranking的serving部分, 只是client部分需要关注一下.
仍然有一点需要重申:
1)生成embeddings, 2)训练模型 以及 3)serving上线 时`jieba`的vocabulary务必保持一致.