An exploded Integer whitens all the data
-1. Update!
So, I finally figured things out after turning to Professor… So when overflow happens, the kernel got killed because GPU may have some internal assertion that will inspect if there’s an overflow.
It’s just a simple nvprof that got me this:
==124906== Warning: Found 2 invalid records in the result.
==124906== Warning: This can happen if device ran out of memory or if a device kernel was stopped due to an assertion.
==124906== Profiling result:
Time(%) Time Calls Avg Min Max Name
100.00% 29.403us 1 29.403us 29.403us 29.403us [CUDA memcpy HtoD]
Note here there is only one memcpy from host to device, which means what’s been moved into the device doesn’t get moved out and hence the mysterious “whitenning” happened.
0. Background
I am studying a little on GPU (specifically Nvidia ones) these days. And the recent toy problem I worked on was a simple prime number generating algorithm. There are a lot of algorithms to go but since my goal is around GPU so I just took an unsalted version with little optimization, the Greek one called Sieve of Eratosthenes.
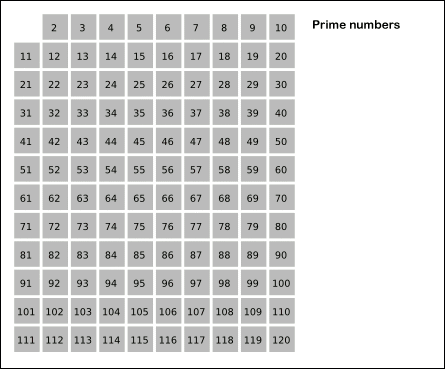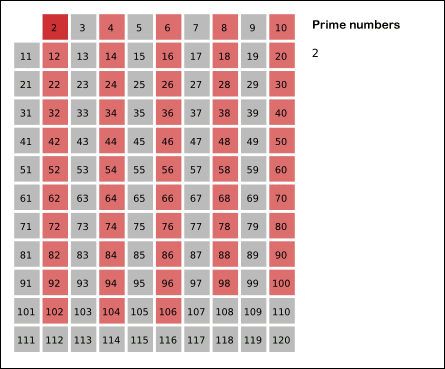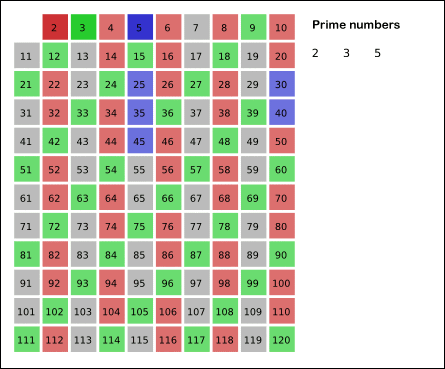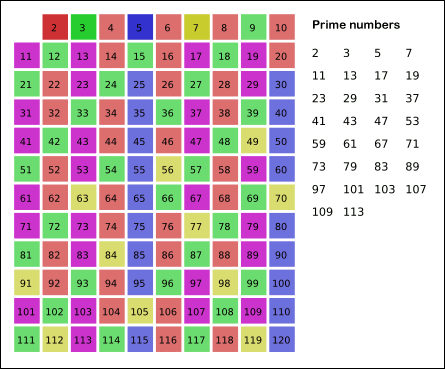
source: wikipedia
1. The Problem
The algorithm in pseudocode is straightforward:

source: wikipedia
So far it seemed all right huh? Oh you just spotted a pitfall? You are welcome with my boxes in the image :)
For a slightly better performance which turned out to be the trigger of overflow (and this blog), we can replace the i < sqrt(N) computation by i * i < N (In the below code snippet, the i takes the name of multiplier, and N is just size + 2 since I don’t count the trivial 1 and 2). Then…
Overflow time!
/*
bang when `multiplier` reaches ceil(sqrt(2^31)) = 46341
*/
/*
which is when `N` gets to (46341-2-1)*2 + 2 = 92678
*/
__global__ void CUDACross(bool *candidates, int size){
for (int idx = blockIdx.x*blockDim.x + threadIdx.x; idx < size/2 + 1; idx += blockDim.x * gridDim.x) {
int multiplier = idx + 2;
int check = multiplier * multiplier;
while (check < size + 2) {
candidates[check - 2] = false;
check += multiplier;
}
}
}
2. The Scene
I was originally thinking that even when overflows, those composite numbers got crossed out before overflow should not be affected. But mysteriously when overflow happens, the whole bulk data come out as untouched. Nothing got crossed!
It turned out oddly there was a clear cleavage of correct and error, precisely at N = 92678. The weird behavior was quite steadily reproducible when I tested with varying input sizes. And it was so reproducible that made me believe it was indeed a bug in my code, not in third party libraries cuz I didn’t include any, surely not in system libraries cuz they never betrayed me, and absolutely not in the compiler or processor cuz I ran the program not with my machine…
More experienced programmers know very well that the bug is generally in their code: occasionally in third-party libraries; very rarely in system libraries; exceedingly rarely in the compiler; and never in the processor.
The behavior when such integer overflow happens is weird, all the changes you have made are gone… I suspect it is designed so for some reason I don’t know. I think I understand now the words from Prof. Z. who is teaching us GPU that
Nvidia likes to make themselves mysterious.
3. Want to play with it?
3.1 Requirements
I tested on both GeForce GTX TITAN X and GeForce GTX TITAN Z and got the same behaviors. No guarantee on other machines but I am willing to bet.
3.2 Codes
I pointed to the repo related if you want to play with. It should be easy to reproduce the results.
You should see a clear cleavage when N = 92678. When N < 92678, all good; once N >= 92678, nothing got crossed out. (by “crossed out/crossed” I mean deleted from candidate list)
To test if all numbers are correct, you can use evaluate.py:
$ python evaluate.py --gold 1stmillion.txt --test [YOUR_OUTPUT]
to see a fraction of the output, lets say from char position 12 through 25, you can use:
$ cut -c 12-25 [YOUR_OUTPUT]